









Select Your Favourite
Category And Start Learning.
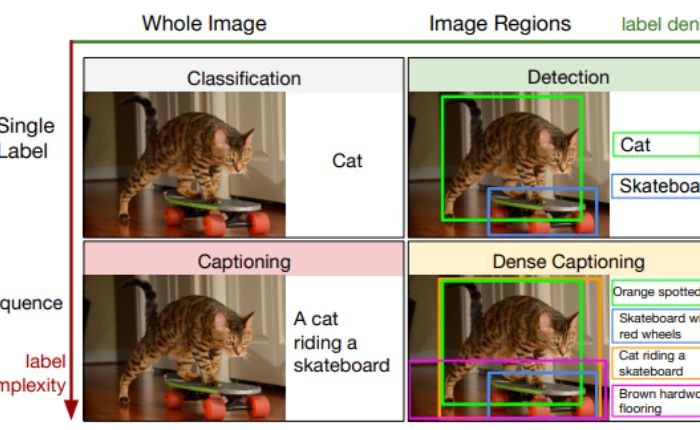
Visual Recognition and Image Captioning
Course content
Week 1-2: Introduction to Computer Vision and Deep Learning
Overview of computer vision and deep learning applications
Convolutional neural networks (CNN) and backpropagation algorithm
Hands-on exercises on building and training deep learning models in TensorFlow or PyTorch
Week 3-4: Image Classification and Object Detection
Week 5-6: Transfer Learning and Fine-tuning
Week 7-8: Image Captioning and Attention Mechanisms
Week 9-10: Visual Question Answering (VQA)
Week 11-12: Advanced Topics and Project Work
About Course
Visual recognition and image captioning are two related fields within computer vision that involve analyzing and understanding visual information in images.
Visual recognition, also known as image classification, is the task of assigning a label or category to an image based on its content. This can involve recognizing objects, scenes, or other visual patterns in the image. In recent years, deep learning models such as convolutional neural networks (CNNs) have shown great success in image classification, achieving near-human performance on many benchmark datasets.
Image captioning, on the other hand, is the task of generating a natural language description of an image. This involves not only recognizing the objects and scenes in the image, but also understanding their relationships and generating a coherent sentence to describe them. Image captioning requires a combination of computer vision and natural language processing techniques, and is often tackled using deep learning models such as convolutional neural networks and recurrent neural networks (RNNs).
Instructor
Student Ratings & Reviews



















